VMware Cloud on AWS Optimizations in Storage-bounded environments. Part 2. Optimize VMC on AWS infrastructure.
So, we come to the second part. You've done all the steps in part one, but you still need more space (or you realize that you can reduce the number of hosts from Compute perspective, but not Storage). Then you need to start optimizing the VMC on AWS infrastructure itself. There will be three main steps here, just like in the last article - optimize storage policies, optimize host types and vSAN type, and optimize clusters.
Storage Policies.
SLA-compliant storage policies.
Note: This part is dedicated exclusively to vSAN OSA based clusters as the main architecture used at the moment. I will talk about vSAN ESA later.
Many customers use Managed Storage Policies by default. This is a Storage Policy that is created (and changed) automatically, depending on the size of your cluster, to meet SLAs. This is convenient, but not always optimal in terms of storage efficiency. The fact is that the default policy is as follows:
- Single AZ - Mirror FTT=1 if hosts from 2 to 5, and RAID6 for 6+ hosts.
- Multi AZ (Stretched Cluster) - if there are less than 4 hosts (i.e. Up to two in each AZ) then no local copies, if there are more than 6 hosts (i.e. From 3 in each AZ) then Mirror FTT=1 within each AZ. Plus of course a copy between AZs.
Now if you look at the VMC/A SLA document, it says the following:
- For non-stretched clusters, you must have a minimum configuration for all VM storage policy Numbers of Failures to Tolerate (FTT) = 1 when the cluster has 2 to 5 hosts, and a minimum configuration of FTT = 2 when the cluster has 6 to 16 hosts. This is not dependent on RAID levels.
- For stretched clusters with four hosts or less, spanning across more than one availability zone, you must have a minimum configuration for all VM storage policy Site Disaster Tolerance (PFTT) = Dual Site Mirroring.
- For stretched clusters with six hosts or more, spanning across more than one availability zone, you must have a minimum configuration for all VM storage policy Site Disaster Tolerance (PFTT) = Dual Site Mirroring and Secondary level of failures to tolerate (SFTT) = 1. This is not dependent on RAID levels.
Note the phrase "This is not dependent on RAID levels", i.e. you can change the FTT Method (between Mirroring and Erasure Coding) as you like and meet the SLA requirements, as long as the FTT is not less than the required for your cluster size.
Let's start with Single AZ case and now turn to the table where we can see the available vSAN Storage Policies for Single AZ for each number of nodes and the capacity overhead from each of them:
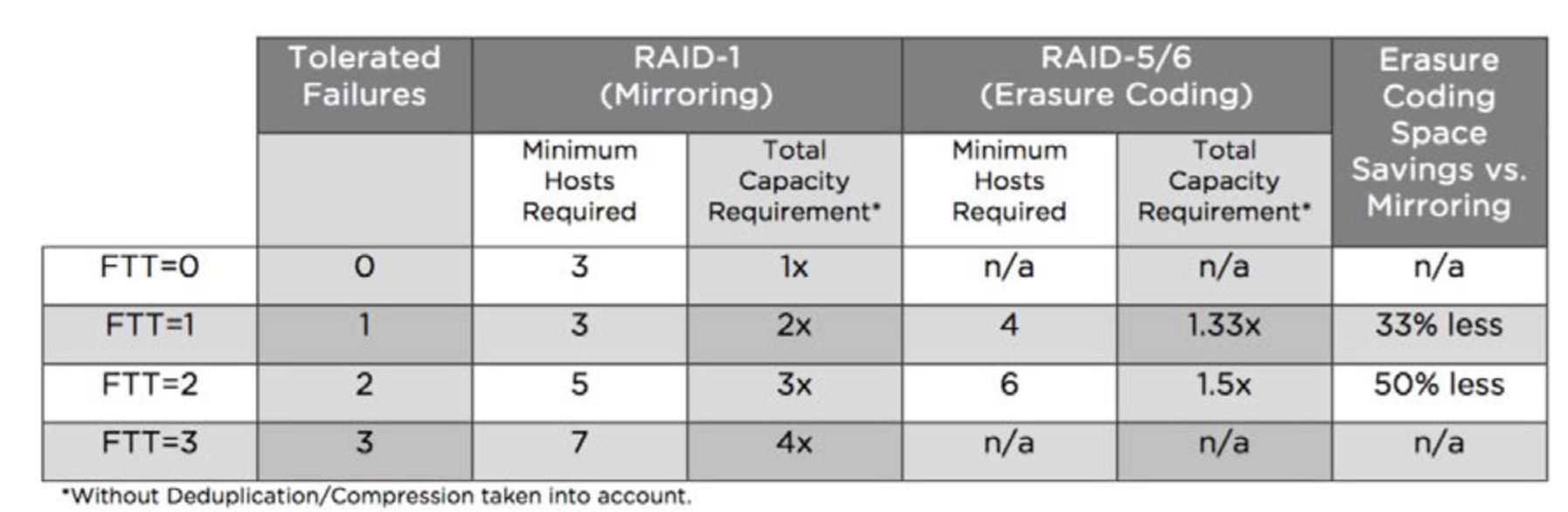
We can clearly see that for 6+ nodes, the most efficient policy used (since we need FTT=2) is RAID 6 with overhead 1.5. But for small clusters of 2 to 5 nodes, Mirror with x2 overhead is used, even though RAID5 with 1.33 is available for cluster sizes of 4-5 nodes.
Now for Multi-AZ (Stretched Cluster) a similar table is here. I won't give you the whole table because it's quite long, but it's obvious that for clusters larger than 8 nodes (i.e. 4+ in each AZ) we can use RAID5 instead of Mirror. This will reduce our total overhead (including copies between AZs) from x4 to x2.66, i.e. almost by half.
I realize that numbers in this form can be hard to take in, so I made a spreadsheet for clarity:
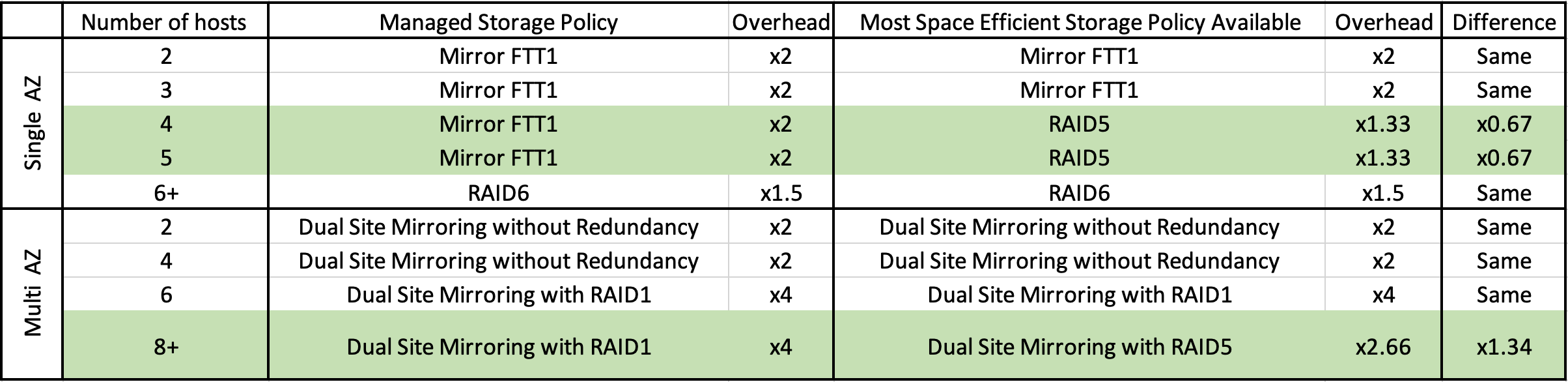
As a result, if your cluster size is within the range marked in green, you can gain additional capacity simply by changing your storage policy. But of course, everything has a price, so I'll point out the disadvantages of this approach:
- For Single AZ, you will have to manually monitor cluster size and change the policy if your cluster grows to 6 nodes or more to meet SLA requirements.
- Performance of RAID5 in OSA is lower than for Mirror (especially in terms of latency). Therefore, the most performance and latency critical workloads may need to be left on Mirror. As always, mileage may vary and look at your workloads and test.
- Changing the policy from Mirror to Erasure Coding (RAID5, RAID6) can take a relatively long time, while putting additional load on vSAN. So, the general recommendation is the quite standard - apply the policy not to all VMs at once, but one by one and do it not at the time of peak workloads.
Storage policies non-compliant with SLA requirements.
Another way (however risky and not always appropriate) is to break the SLA requirements and make the storage policy even more cost-effective. Here again we will refer to the document describing SLA in VMC on AWS. The following line can be found there:
"If an SLA Event occurs for your SDDC Infrastructure, it applies to a cluster within the SDDC. For each SLA Event for a cluster, you are entitled to an SLA Credit proportional to the number of hosts in that cluster."
I.e. SLA for workloads is evaluated for each cluster separately. This means that we can create a separate cluster for our non-critical workloads or those workloads where we are not interested in SLA compliance and are ready to take risks. At the same time, the workloads on the main/production clusters will still be subject to SLA conditions, if Storage Policy there is complaint. For sure we can do this for main/production cluster as well but it's even more extreme scenario.
I will not repeat all the calculations I did above, simply because they are completely similar, and I will give you the final table separately for Single AZ and Multi AZ. In it I have marked in red the fields where we don't have any data protection and in green where we have at least one copy.
Non-complaint Storage Policies for Single AZ

You can clearly see that the only way to save capacity in any meaningful way is to switch to FTT0, since the other options do not provide any significant savings and also break the SLA. As a reminder, FTT0 means that you will only have a single copy of your data. This means that in case of any failure (disk failure, node failure) you will lose your data with no possibility to recover it. Moreover, since data placement on disks/nodes is done automatically by vSAN itself based on the current disks utilization and you cannot control it (vSAN Host Affinity feature is not available in VMC on AWS), you can't protect workloads also at the application level. The disks of two VMs of the software cluster can be located on the same node and if it fails, you will lose both copies. And the only way to protect the service/data is to place VMs of the software cluster on different vSAN clusters, which is not always convenient and makes sense, and also you will have to manually recreate VMs and rebuild the software cluster. While this is possible, I suggest agreeing on that all VMs/services hosted with FTT0 policy will lose data if any failure happen.
In this case, this means that there are fundamentally several main types of candidates to be placed on FTT0 - stateless services, workloads that can be easily recreated or that are unimportant, and their failure does not have any impact on the operation.
As an example of stateless services, I can mention caching stateless services or data analysis that is performed on a copy of the data (and the original data is stored in a durable storage). In this scenario, if a failure occurs, we risk either losing some performance or just the time it takes to restart the job, which in some cases is quite acceptable. Test environments for automated testing can also be considered as an example of suitable workloads. For them similarly, in case of failure it will be enough to restart the test. Other "unimportant workloads" include various test environments, temporary workloads, etc. In general, a good indicator of applicability are two factors - whether a backup of this system doesn't exist (or rather is not needed) or how long it will take to redeploy the VM to restore its function.
But as usual, evaluation criteria and their importance are different for everyone, so carefully and individualistically approach this task and consult with the application/service owner. The last thing I would like to point out is that using FTT0 not only saves a lot of space, but also allows for significant performance improvements, even compared to Mirror FTT1. So that may be an additional factor.
Non-complaint Storage Policies for Multi AZ
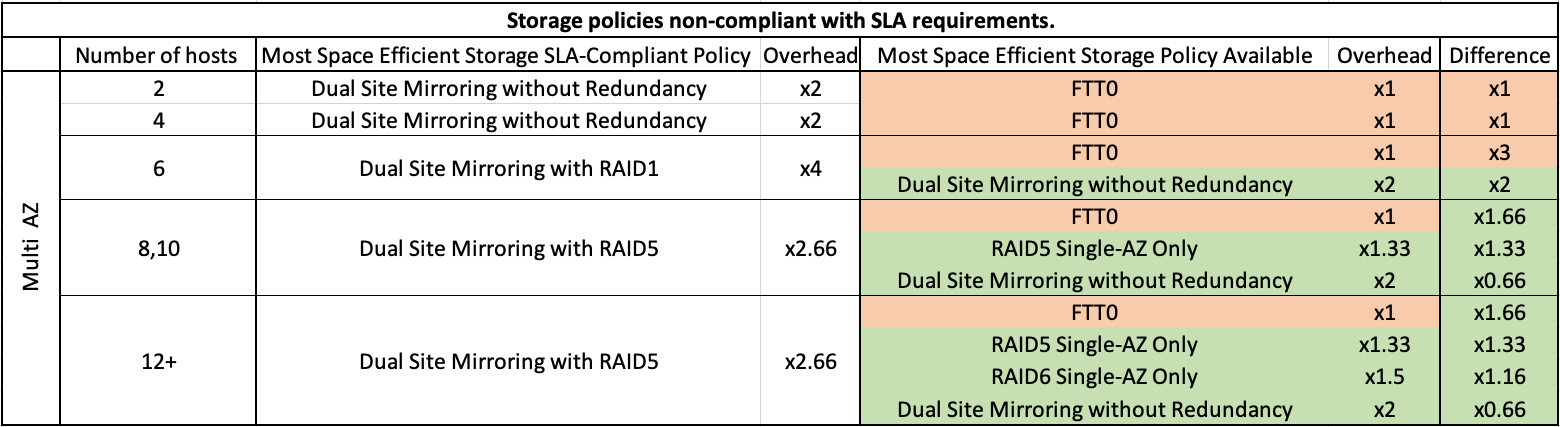
But in the stretched cluster scenario, we see that the situation is fundamentally different. The point is that in VMC on AWS, all clusters within a single SDDC must be of the same type - either all MultiAZ or all Single AZ. Having said that, it is obvious that availability requirements can vary significantly and not all workloads in a company may require AZ failure protection. Also, in a stretched cluster, SLA compliance requires mirroring between AZs, which is not space efficient (x2) and also adds latency to writes due to synchronous replication to the second AZ.
So, first of all, you can of course use FTT=0, but the considerations are completely similar to the last paragraph, so I won't dwell on that again, but instead consider the scenario where we still want data protection, but we are happy with protection against any single failure or even two.
In the first case, for clusters larger than 6 nodes (3 at each site) you may not use local copies (within AZs), but only replicate between AZs. So, it works out like a normal Mirror FTT=1 (and similar to the scenario where you have less than 6 nodes in the stretched cluster), and the systems will still be available if one of the AZs fails. If a separate host failure occurs, the data will be available from the second AZ (but keep in mind this will add latency on reads equal to RTT because there will be no more local read until the rebuild is complete).
In the second case, we don't protect the data from AZ failure, but we store local copies within the AZ. And you can store them not only as a mirror, but also using Erasure Coding (RAID5, RAID6) if you have enough nodes to do so (4+). This means that you can use the space more efficiently and also provide protection against up to two failures. Also, in terms of performance you have no additional latency due to writing to the remote AZ. The downside to this approach (aside from the obvious lack of AZ crash protection) is that you have to manually monitor the capacity in each AZ and manually place VMs on one or another AZ. Also, to avoid reads from a remote AZ, use VM-Host Affinity Compute Profiles to ensure that VMs are running where their data resides.
Migrate to vSAN ESA-based clusters.
VMC on AWS 1.24 introduced support for vSAN Express Storage Architecture (ESA). An overview of this biggest change since vSAN version 1.0/5.5 is here, but I'll give the main differences:
- New architecture for local disk handling (LSOM) - no more Disk Groups with separate cache and capacity disks. Now all host disks are a single pool, each providing both usable capacity and performance.
- New Erasure Coding (RAID5/6). All writes go first to the small Performance-leg components in Mirror, then the data from them is written full stripe to the Capacity-leg in the EC. In short, this allows for performance (in terms of both latency and IOPS) similar to Mirror for EC.
- Data Services such as compression and encryption now operate at the individual object level (DOM-layer) rather than at the disk group level. This allows for a significant reduction in overhead, as well as more granular management.
- Very long-awaited performance penalty-free snapshots. Now there is no impact from creating, storing a chain of snapshots, as well as deleting them.
I've deliberately simplified a lot of things and also left a lot out, but if you're interested in the details go here.
Getting back to our topic of optimizing storage capacity in VMC on AWS, here are the following advantages that ESA has over OSA:
- Each disk in the host now provides capacity, which increases the total available capacity. Previously some of the disks only acted as a write buffer and did not contribute to persistent storage.
- The new Erasure Coding allows it to be used for all workloads without exception from performance point of view. And since Erasure Coding is more efficient than Mirror, it allows you to gain additional space if previously some data was stored in Mirror due to performance considerations.
- Introduced a new RAID5 level with a 2 data + 1 parity scheme. This allows to use R5 (2+1) with x1.5 overhead already on three nodes, where previously only Mirror with x2 was available and RAID5 required a minimum of four nodes. There is also available R5 (4+1) scheme with x1.2 overhead.
- Much more efficient compression. In ESA, each 4K is compressed in 512b increments. I.e. 4K, 3.5K, 3K, ..., 512b are possible. This significantly increases compression efficiency, because in OSA the mechanism is different - if a 4K block is compressed by 50% or more, exactly 2K is written, and if less, the original 4K block is written. In ESA we not only get the possibility to increase the maximum compression up to 8x (against 2x in OSA), but also because of intermediate values the average compression ratio increases significantly.
- As I wrote in the last article, TRIM/UNMAP is enabled by default.
If we compare the available usable capacity on the first/main ESA-based cluster (so counting capacity for management components) with an OSA-based (with the most efficient SLA-compliant storage policy) with the same compression efficiency, we get the following values:
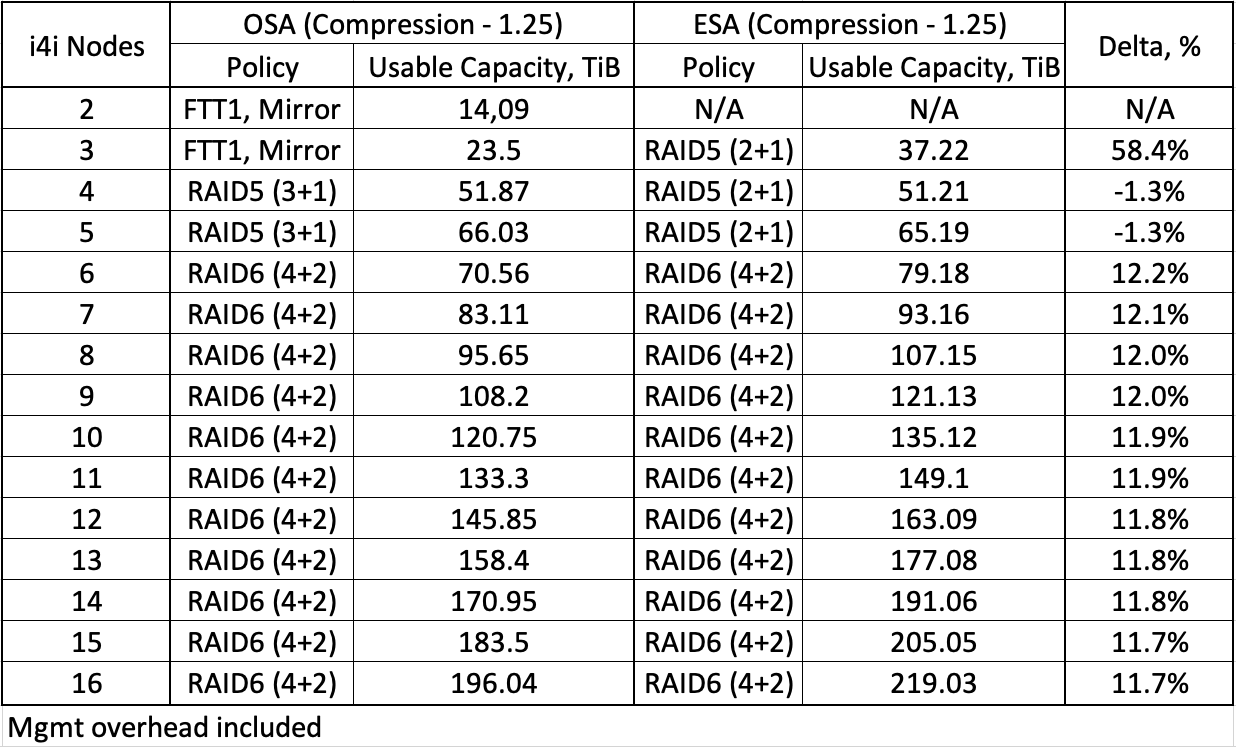
You can clearly see that the largest effect (almost 60%) is on the 3-host cluster due to the new Erasure Coding 2+1. For all clusters starting with 6 hosts there is about 12% more available space due to the absence of dedicated cache disks (in both cases using RAID6 4+2). However, for four and five hosts clusters there is almost no difference (technically minus ~1%) - this is due to the fact that ESA has no 3+1 RAID5 scheme, so the efficiency for ESA is 1.5 vs. 1.33 in OSA, which compensates for more raw storage available.
In addition, you can get better compression efficiency on top. Unfortunately, there are no public numbers on average compression ratios yet and VMware is still gathering data based on the early real customer installations of ESA-based clusters in VMC on AWS, but it's pretty clear that it will be better than OSA and the question is just how much better. Also note that compression is now a storage policy level setting, not a cluster-wide setting. So, you can disable it for individual VMs where you don't expect any compression - such as already compressed databases, media files, data encrypted at the guest OS or application level.
It's hard to think of any particular disadvantages of vSAN ESA over OSA that would be relevant for use in VMC on AWS, but there are limitations that may currently make it impossible to use:
- SDDC must be updated to the latest currently available version 1.24
- Only i4i nodes are supported. ESA is not available on i3, i3en and of course on M7i (because there are no disks at all).
- Stretched cluster / Multi-AZ including the particular case of a 2-node cluster is not supported at the moment.
If you don't fall within these limitations, the obvious recommendation is to go to ESA.
Migration from OSA to ESA
Currently, in-place migration is not supported, so there are two ways to migrate data from OSA to ESA.
The first is to create a new separate cluster based on ESA, migrate (vMotion, Cold Migration, etc) VMs from the current clusters to the new one, then remove nodes from the OSA-based clusters. This works fine for not the primary/first cluster, but all those that were created additionally. And for the primary cluster, there's the problem that you cannot migrate management components this way. In this case, you can do the following - move all (or almost all, to make the most efficient use of available resources) the productive workloads and leave the first cluster on OSA as the minimum possible management cluster (e.g., two nodes). This usually makes sense if you have a large enough number of hosts in VMC on AWS and/or if the benefit of moving to ESA (and reducing the number of nodes required as a result) outweighs the cost of creating a dedicated management cluster (but don't forget that if you place management components on a shared cluster, resources are still consumed there and therefore cannot be allocated to workloads and this should be taken into account). There are other benefits to building a dedicated management cluster, such as isolating production workloads from management workloads, but that is a bit beyond the scope of this article. Great document about planning management cluster in VMC on AWS is here.
The second option, which is particularly well suited for smaller VMC on AWS installations, is to create a new SDDC based on ESA. While this is noticeably more time-consuming (because at a minimum, you'll need to migrate network settings, security, etc.), if the infrastructure in VMC on AWS is simple and/or small enough, it can make sense. When you need it and what it can give you:
- You can migrate your entire infrastructure to an ESA, including the first/primary cluster.
- You need or want to run VMC on AWS in a different region (due to price or business requirements).
- You need or want to move from Single-AZ SDDC to Multi-AZ SDDC or vice versa.
- You see the value or need to change Subnets for Management network and/or AWS VPC.
- You need or want to change the host type. Although you can do this in the current cluster/SDDC as well, here it will be done at the same time.
- First, you don't have to wait for your SDDC to be updated to 1.24.
A document that describes one option for such a migration is available here.
Optimize Host Type.
There are currently four node types available* in VMC on AWS:
- i3 is the very first and probably still the most popular node type. These are General Propose nodes with a balanced ratio of capacity and compute resources. But in January 2023 it was announced that these nodes are no longer available as Reserved Instances, but many customers are still using them as they were purchased before and are still in use.
- i4i - these nodes came to replace i3 in summer 2022. In terms of resources this is a doubled i3, but based on much more modern hardware. You could say that these are now the main type of hosts and are being migrated to from i3.
- i3en - Storage-heavy hosts. They are popular with customers who need to store a lot of data relative to compute resource requirements.
- M7i - The newest nodes that were announced in November 2023. The distinguishing feature is that they do not use local SSDs and vSAN but storage resources are provided based on VMware Flex Storage or FSx for NetApp ONTAP. At the time of this writing, they are in Tech.Preview and are only available in a limited number of regions.
It is sometimes the situation that when VMC on AWS infrastructure is calculated, the resource requirements are not yet fully known, or they may have changed since the project started. Also, at the time of original host procurement, some host types (e.g. i4i or m7i) may not be available yet, so current clusters may not be built on the optimal host type.
Second, after making optimizations in terms of storage capacity, your requirements may have decreased as well as your Compute to Capacity ratio.
And finally, as you use VMC on AWS, your competency has grown, as well as your understanding of your workloads and how VMC on AWS matches them.
Therefore, one way to further optimize costs is to distribute your workloads across the most optimal types of nodes and clusters. And while for relatively small VMC on AWS installations you should consider simply converting the cluster to other nodes in the first place, for larger installations it makes sense to create separate clusters for different tasks based on different types of nodes.
Therefore, one way to further optimize costs is to distribute your workloads across the most optimal types of nodes and clusters. And while for relatively small VMC on AWS installations you should consider simply converting the cluster to other nodes in the first place, for larger installations it makes sense to create separate clusters for different tasks based on different types of nodes.
Unfortunately, there is no one-size-fits-all solution on how to do this optimization, but I will show you a way that will allow you to simplify this task a bit:
- Make an inventory of all VMs in your VMC on AWS. You can do this by doing a custom report in Aria for Operations or RVTools and upload it to an excel file. There should be a list of VMs and the main characteristics of the VM (vCPU, RAM, Usable Storage).
- Divide all workloads into several classes. Obviously, it makes sense to classify by workload type - Production, Test/Dev, VDI, etc, but from the point of view of capacity optimization it is interesting to understand the requirements for the storage subsystem. I propose to categorize them as follows:
- Large (in terms of capacity) VMs, but which do not have special requirements for disk subsystem performance, as well as Compute. These are candidates for migrating to External NFS (I will cover this in the next article) with i4i or possibly M7i (if they are already available in your region).
- Large VMs (in terms of capacity footprint), but which require a fast storage subsystem and/or have tight latency requirements. For example, Databases. These are candidates for i3en type nodes.
- VMs with high requirements in terms of Compute, but minimal requirements for the storage subsystem. These are candidates for i4i or M7i
- All other VMs without any special requirements.
- Calculate the total resource requirements for each type.
- Try to allocate them to clusters of different types. Use VMC Sizer for this purpose. Great guide about VMC Sizer is here. Your task is to minimize the total cost of all nodes. You can usually achieve this by utilizing all resources on each cluster as evenly as possible. I would suggest that you start with i4i to check if everything can be placed there. If not, remove storage intensive workloads (as candidates for i3en) and check again. If you see that the amount of workloads is enough to make sense to dedicate a separate cluster, then try that. And further, to fill evenly, both in terms of compute resources and capacity, then add individual workloads from category 4 until you achieve more or less even utilization.
- Evaluate the cost of all the resulting nodes. If it is lower than it is now, then consider how much it makes sense to shift the workloads (taking into account the increased complexity of infrastructure management, scaling, etc). If this does not reduce the cost, then look at what is making a noticeable contribution and try redistributing again.
In general, it's such an interactional process and with no guarantees that optimization will actually work. As a rule, it works only on sufficiently large infrastructures, when it is possible and makes sense to create several large clusters.